MVVM의 기원: Presentation Model (by Martin Fowler)
많은 개발자가 MVVM을 마이크로소프트가 WPF를 위해 만든 최신 패턴으로 알고 있지만, 그 뿌리는 2004년 마틴 파울러가 제안한 ‘Presentation Model’에 있다. 이 개념을 이해하면 SwiftUI가 왜 지금의 형태가 되었는지 더 명확해진다.
1. MVVM은 사실 ‘Presentation Model’의 마케팅 용어다
- 역사적 배경: 2004년 당시에는 iOS도 없었고, 마틴 파울러는 Windows Forms를 예로 들어 이 패턴을 설명했다.
- 용어의 변화: 이후 마이크로소프트가 WPF를 내놓으면서 이 패턴을 가져다 쓰고 ‘MVVM’이라는 세련된 이름을 붙여 마케팅한 것이다. 즉, 두 개념은 본질적으로 같다.
2. 과거 개발자들을 괴롭혔던 문제: ‘동기화(Synchronization)’
마틴 파울러는 아티클에서 Presentation Model의 가장 번거로운 작업으로 ‘View와 Model 사이의 동기화’를 꼽았다.
- 과거의 방식: UI의 텍스트 박스 값이 바뀌면, 개발자가 직접 코드를 짜서 모델의 값을 업데이트하고, 반대로 모델이 바뀌면 UI를 갱신하는 코드를 일일이 작성해야 했다.
- 지루한 반복: 단순한 데이터 전달임에도 불구하고, 모든 UI 컨트롤마다 이런 ‘보충 코드’를 짜는 것은 매우 지루하고 에러가 나기 쉬운 작업이었다.
3. 프레임워크의 진화: 자동 바인딩(Automatic Binding)의 등장
마틴 파울러는 “언젠가 프레임워크가 이 보충 코드(보링 코드)를 대신 처리해줄 날이 올 것”이라고 예견했다.
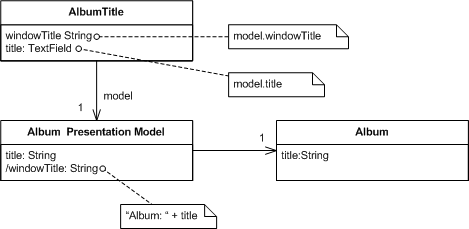
- WPF의 등장: 마틴의 예언대로 WPF가 나오면서 XAML(View)과 C#(ViewModel) 사이의 양방향 바인딩(Two-way Binding)을 프레임워크가 자동으로 처리하기 시작했다.
- 현대의 기술: 이제 우리가 쓰는 SwiftUI, React, Flutter에서는 이 ‘동기화 로직’을 고민할 필요가 없다. 프레임워크가 상태(State)의 변화를 감지하여 UI를 자동으로 그려주기 때문이다.
4. 왜 2004년 글을 읽어야 하는가?
우리가 당연하게 사용하는 @State, @Binding, @Published 같은 것들이 사실은 “어떻게 하면 개발자가 일일이 동기화 코드를 짜지 않게 할까?”라는 20년 전의 고민을 해결한 결과물이기 때문이다. 이 역사적 맥락을 알면 MVVM의 각 컴포넌트(Model, View, ViewModel)가 왜 분리되어야 하는지 그 당위성을 더 깊이 이해할 수 있다.
[참고 사이트]
MVVM 디자인 패턴의 이해
MVVM은 모델(Model), 뷰(View), 뷰모델(ViewModel)로 구성되며, 각 계층의 역할을 명확히 나누어 앱을 더 체계적으로 설계하기 위한 패턴이다.
1. 모델 (Model): 앱의 두뇌
모델은 단순한 데이터 덩어리가 아니라, 앱의 비즈니스 로직과 도메인 객체를 담당하는 핵심 계층이다.
- 로직의 중심: 예를 들어 ‘주문’ 모델이라면 이메일, 가격 같은 속성뿐만 아니라 할인 적용, 수량 업데이트 같은 메서드(액션)를 직접 가지고 있어야 한다.
- 테스트 가능성: 앱의 가장 중요한 로직들이 모여 있는 곳이므로, 유닛 테스트를 수행할 때 가장 집중적으로 다뤄야 하는 부분이다.
2. 뷰 (View): 사용자 인터페이스
뷰는 사용자가 눈으로 보고 상호작용하는 모든 시각적 요소다.
- 시각적 표현: 로직은 배제하고 데이터를 화면에 그리는 역할에만 집중한다.
- 다양한 기기 대응: 동일한 모델 데이터를 바탕으로 iPhone, Apple Watch, macOS 등 각 기기에 맞는 UI를 제공한다.
3. 뷰모델 (ViewModel): 중계자
뷰모델의 주된 임무는 모델에서 데이터를 가져와 뷰가 사용하기 좋게 가공하여 전달하는 것이다.
- 데이터 전달: 모델의 복잡한 데이터를 뷰가 바로 쓸 수 있는 단순한 형태로 변환한다.
- 혼동 주의: 많은 개발자가 뷰모델의 역할을 어렵게 생각하지만, 본질은 모델의 데이터를 뷰로 이어주는 ‘통로’ 역할이다.

4. 네트워크 통신에서의 데이터 흐름 (DTO의 역할)
서버와 데이터를 주고받을 때는 순수 모델과는 성격이 다른 DTO(Data Transfer Object)가 등장하며 흐름이 구체화된다.
- 뷰가 뷰모델에게 데이터를 요청한다.
- 뷰모델은 네트워킹 클라이언트를 통해 서버에 접근한다.
- 서버는 로직이 없는 순수한 데이터 객체인 DTO를 반환한다.
- 뷰모델은 이 DTO를 받아 뷰에 표시할 준비를 하고, 최종적으로 뷰에 전달하여 화면에 출력한다.
이처럼 MVVM은 역할을 명확히 나누어 복잡한 앱을 관리하는 데 유리하지만, 모든 프레임워크에서 만능인 것은 아니다. 특히 SwiftUI의 선언적 특성과 만났을 때 어떤 제약이 생기는지 이해하는 것이 중요하다.
MVVM의 한계: 왜 SwiftUI와 충돌하는가?
전통적인 MVVM 방식은 SwiftUI의 선언적(Declarative) 특성과 만났을 때 오히려 불필요한 복잡성을 초래하고 유지보수를 어렵게 만든다.
1. 1:1 대응으로 인한 코드의 비대화 (Massive View Models)
- 문제점: 화면(Screen)이 하나 추가될 때마다 대응하는 뷰모델을 무조건 생성하는 방식은 비효율적이다.
- 결과: 소규모 앱에서도 5개 화면에 5개 뷰모델이 생기며, 앱이 커질수록 수십 개의 뷰모델을 관리해야 한다. 이는 관리 포인트만 늘리는 결과를 초래한다.
2. 다중 데이터 소스(Multiple Sources of Truth)의 문제
- 전통적 방식: 각 뷰모델이 각각 서버와 통신하며 데이터를 들고 있음으로써, 동일한 서버 데이터를 참조하는 여러 개의 ‘상태(State)’가 앱 내에 파편화된다.
- 실제 진실의 근원: 클라이언트-서버 앱에서 유일한 Source of Truth는 ‘서버’여야 한다. 뷰모델을 남발하면 이 원칙이 깨지기 쉽다.
3. SwiftUI 기능 활용의 제약 (EnvironmentObject의 부재)
- 계층 구조의 한계: SwiftUI의
EnvironmentObject는 뷰 계층 안에서만 유효하다. - 복잡한 주입: 뷰모델 안에서는
EnvironmentObject에 직접 접근할 수 없으므로, 이를 쓰기 위해 복잡한 의존성 주입(Dependency Injection) 코드를 추가로 작성해야 하는 역설이 발생한다.
4. 대안: SwiftUI가 제안하는 방향
[사례 1] 뷰 자체가 이미 뷰모델이다 (View as a ViewModel)
단순히 데이터를 가져와 보여주는 화면이라면, 굳이 뷰모델을 만들지 않고 환경 변수(Environment Values)와 상태(@State)만으로 충분히 구현 가능하다.
- 로직 추출: 복잡한 검증이나 변환 로직이 필요하다면 뷰모델 클래스가 아닌, 가벼운 구조체(Struct)로 분리하여 테스트 가능성을 확보한다.
[사례 2] 통합 모델(Aggregate Model/Store) 활용
화면마다 뷰모델을 만드는 대신, 특정 도메인(예: MovieStore)을 담당하는 하나의 커다란 관찰 대상 객체를 만들어 여러 뷰가 공유하도록 한다.
- Bounded Context: 도메인 주도 설계(DDD) 개념을 도입하여, 업무 경계(예: 카탈로그, 주문, 배송)에 따라 통합 모델을 나누면 코드 양을 획기적으로 줄일 수 있다.
5. 테스트에 대한 새로운 시각
- 뷰모델 테스트의 함정: 뷰모델의 함수가 성공한다고 해서 UI가 제대로 그려진다는 보장은 없다. 뷰모델 테스트는 UI 테스트가 아니다.
- 자신감의 문제: 모든 코드에 강박적으로 유닛 테스트를 짜기보다, 도메인 로직(앱의 두뇌)에 집중하고 나머지는 UI 테스트나 프리뷰를 통해 ‘작동하는 코드’에 대한 확신을 얻는 것이 중요하다.
💡 요약하자면: SwiftUI를 쓸 때는 프레임워크와 싸우지 말고, 프레임워크가 제공하는 강력한 상태 관리 기능을 최대한 활용해야 한다. “코드 파일이 적을수록 자산이 아니라 부채(Liability)가 줄어든다”는 점을 명심하자.